Microservices Lessons From Netflix

🚀 Welcome to the World of Code with Manan Shah! 🌟
Dive into the art of software wizardry led by a seasoned senior software developer with 9 years of expertise. Join me on this thrilling tech journey as we decode the secrets of software, explore cutting-edge trends, and unravel the power of code. Let's craft the future together, one algorithm at a time. 💻✨
Microservices Architecture
Netflix runs on AWS. They started with a monolith and moved to microservices. Their reasons for migrating to microservices were the following:
It was difficult to find bugs with many changes to a single codebase
It became difficult to scale vertically
There were many single points of failures
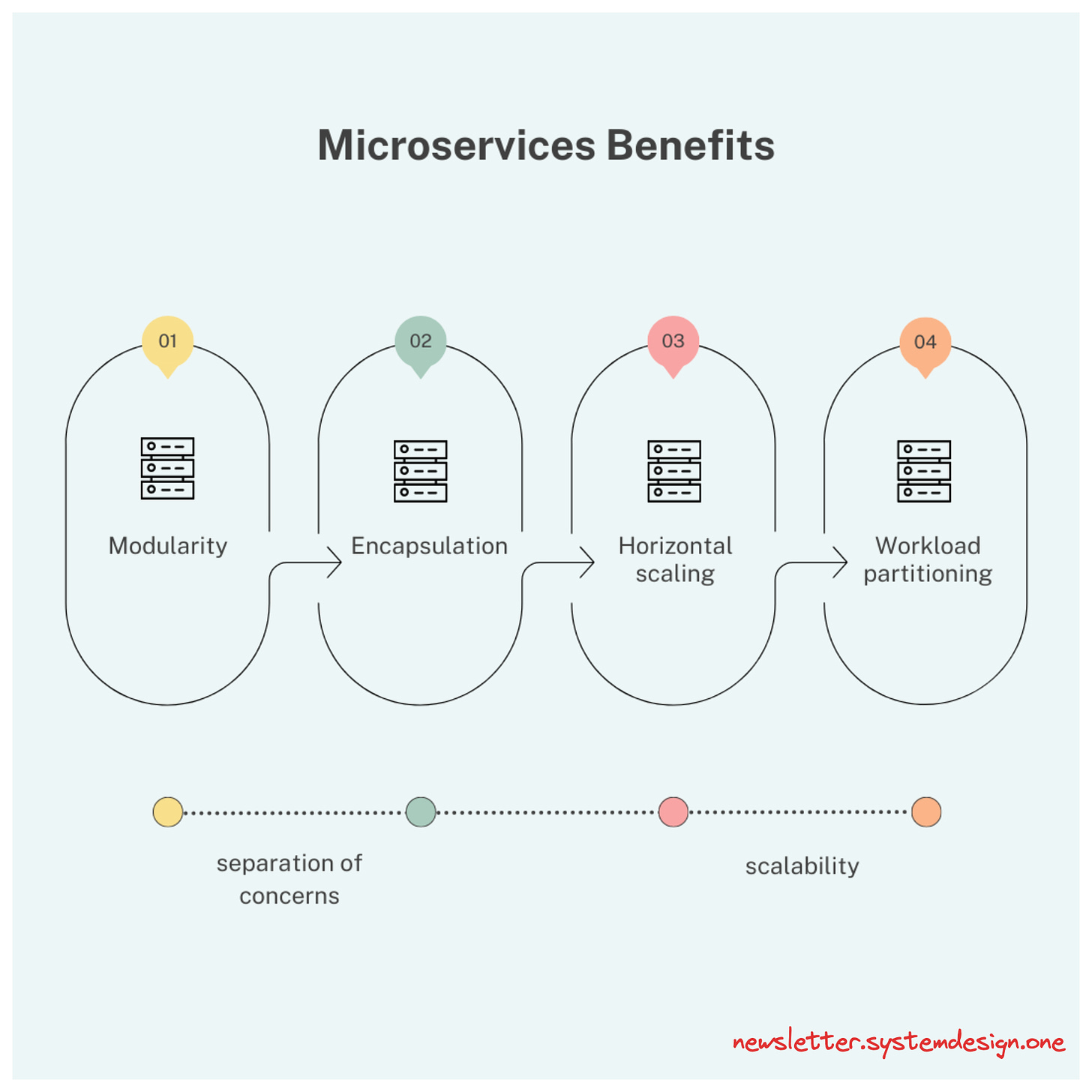
Microservices benefits
This post outlines the Microservices lessons from Netflix.
Microservices Challenges and Solutions
3 main problems with microservices architecture are:
Dependency
Scale
Variance
1. Dependency
Here are 4 scenarios where the dependency problem occurs:
i) Intra-Service Requests
A client request results in a service calling another service. Put another way, service A needs to call service B to create a response.

Intra-service requests
The problem with it is that a failure of a microservice results in cascading failures. The solutions are:
Use the circuit breaker pattern to prevent cascading failures. It avoids an operation that will probably fail
Do fault injection testing to check if the circuit breaker pattern works as expected. It does it by creating artificial traffic
Set up fallback to a static page to keep the system always responsive
Install exponential backoff to prevent thundering herd problem
Yet degraded availability and increased system test scope become a problem. Because availability reduces when the downtime of individual microservices gets combined. And the permutations of test scope grow by a ton as the number of microservices increases.
So it’s important to identify critical services and create a bypass path to avoid non-critical service failures.
ii) Client Libraries
An API gateway allows the reuse of business logic across many types of clients.
An API gateway is a central entry point that routes API requests. But it has the following limitations:
Heap consumption becomes difficult to manage
Potential logical defects or bugs
Potential transitive dependencies
So the solution is to keep the API gateway simple and avoid it from becoming the new monolith.
iii) Persistence
The choice of the storage layer depends on the CAP theorem. Put another way, it is a trade-off decision between availability and consistency level.
So the solution is to study the data access patterns and choose the right storage.
iv) Infrastructure
The entire data center might fail. So the solution is to replicate the infrastructure across many data centers.

Netflix outage; Forbes.com
2. Scale
The ability of the system to manage increased workload while maintaining performance is called scale. The 3 dimensions of horizontal scalability are:
Keep the service stateless if possible
Partition the service if it can't be stateless
Replicate the service
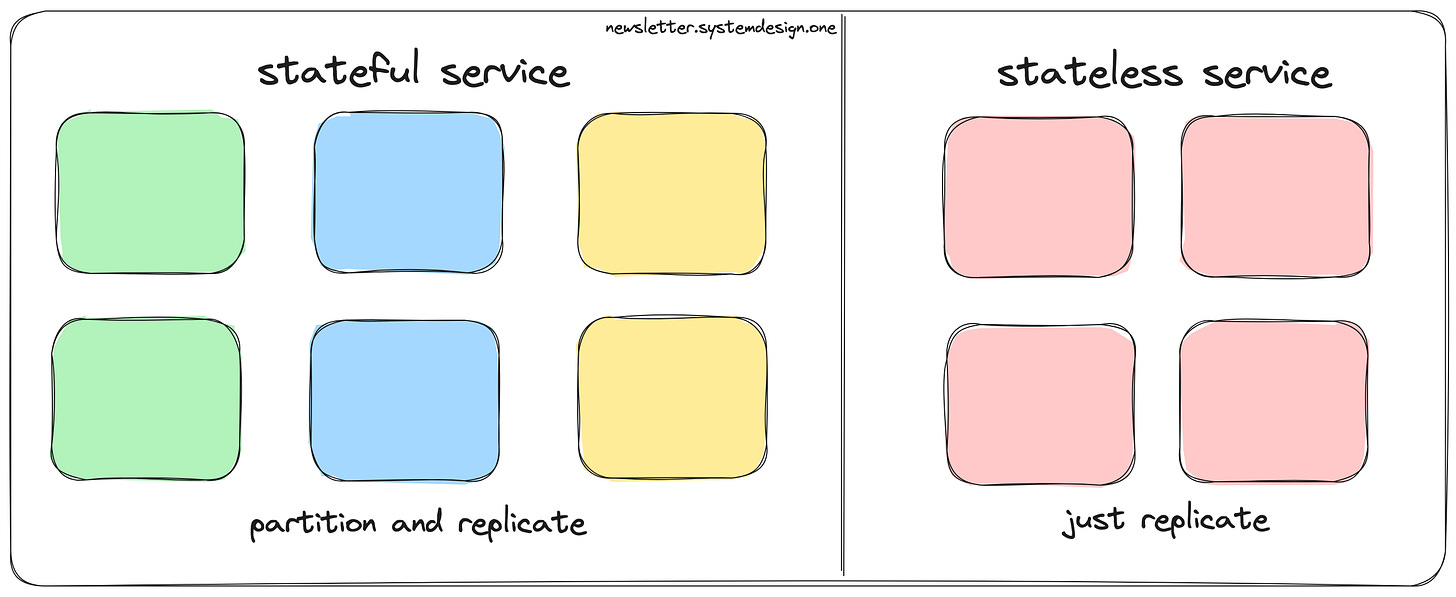
Stateful service and Stateless service
Here are 3 scenarios where the scale problem occurs:
i) Stateless Services
The 2 qualities of stateless service are:
There is no instance affinity (sticky sessions). Put another way, requests don't get routed to the same server
Failure of a stateless service is not notable
The stateless service needs to be replicated for high availability. And autoscaling must be set up for on-demand replication.
Also autoscaling reduces the impact of the following problems:
Reduced compute efficiency
Node failures
Traffic spikes
Performance bugs
The database and cache are not stateless services.
Chaos engineering checks whether autoscaling works as expected. It tests system resilience through controlled disruptions to ensure improved reliability.
ii) Stateful Services
The database and cache are stateful services. Also a custom service that holds large amounts of data is a stateful service. The failure of a stateful service is a notable event.
An anti-pattern with the stateful service is having a sticky session without replication. Because it creates a single point of failure.
The solution is to replicate the writes across many servers in different data centers. And route the reads to the local data center.
iii) Hybrid Services
A cache is a hybrid service. A hybrid service expects an extreme load. For example, Netflix’s cache gets 30 million requests per second.
The best approach to building a hybrid service is the following:
Partition the workload using techniques like consistent hashing
Enable request-level caching
Allow fallback to a database
And use Chaos engineering to check whether the hybrid service remains functional under extreme workloads.
3. Variance
The variety in the software architecture is called variance. The system complexity grows as variance increases.
Here are 2 scenarios where the scale problem occurs:
i) Operational Drift
Operational drift is the unintentional variance that happens as time passes. It is usually a side-effect of new features added to the system. The examples of operational drift are:
Increased alert thresholds
Increased timeouts
Degraded throughput
The solution to this is continuous learning and automation.
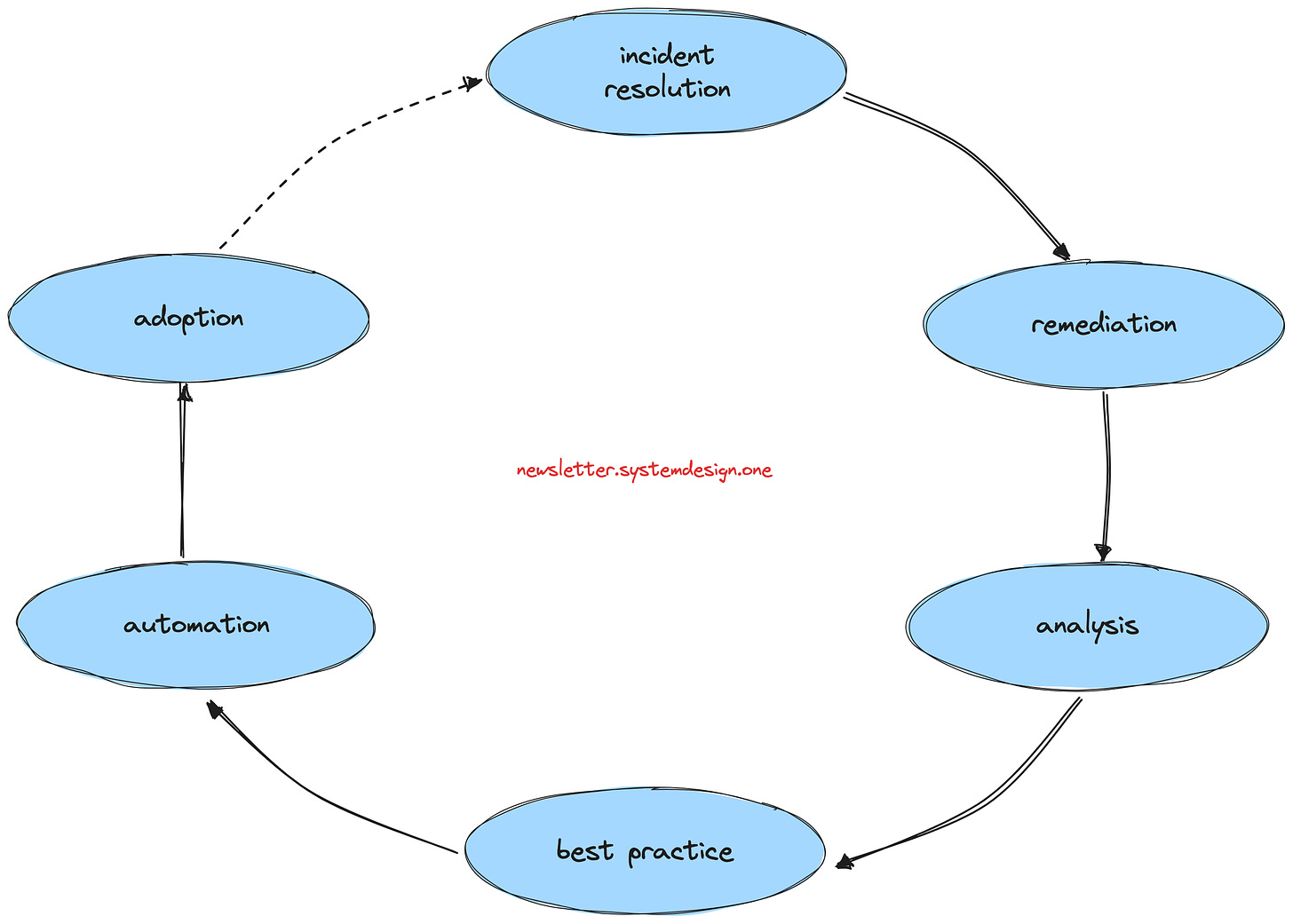
Continuous Learning and Automation
Here is the workflow:
Review an incident resolution
Put remediation in place to prevent it from occurring again
Analyze many incidents to identify patterns
Derive best practices from incident resolutions
Automate the best practices if possible
Promote the adoption of best practices
And repeat
ii) Polyglot
The variance introduced by engineers on purpose is called Polyglot. It happens when different programming languages are used to create different microservices.
It comes with the following drawbacks:
A large amount of work needed to get productive tooling
Extra operational complexity
Difficulty in server management
Business logic duplication across many technologies
Increased learning curve to become an expert
The solution to this problem is to use proven technologies.
Besides polyglot forces the decomposition of the API gateway, which is a good thing. So the best ways to use Polyglot architecture are:
Raise team awareness of the costs of each technology
Limit centralized support to critical services
Prioritize based on the impact
Create reusable solutions by offering a pool of proven technologies
Here is a checklist of best practices for microservices architecture from Netflix:
Automate tasks
Setup alerts
Autoscale to handle dynamic load
Chaos engineering for improved reliability
Consistent naming conventions
Health check services
Blue-green deployment to rollback quickly
Configure timeouts, retries, and fallbacks
Also change is inevitable and things always break with changes. So the best approach is to move faster but with fewer breaking changes.
Besides it's helpful to restructure teams to support the software architecture.